

What is Apache Arrow?
Apache Arrow is growing to be proved to be a successful framework of future data analytics in most highly advanced tech and ecommerce companies.
Apache Arrow is used to accelerate analytic workloads within a particular system when data needs to be exchanged with low overhead. It is flexible enough to support most complex data science models.
What is Apache Arrow?
Apache Arrow is a language-agnostic software framework for developing data analytics applications that process columnar data.
It contains a standardized column-oriented memory format that is able to represent flat and hierarchical data for efficient analytic operations on modern CPU and GPU hardware. This reduces or eliminates factors that limit the feasibility of working with large sets of data, such as the cost, volatility, or physical constraints of dynamic random-access memory (dynamic RAM or DRAM).
What problems Apache Arrow are solving?
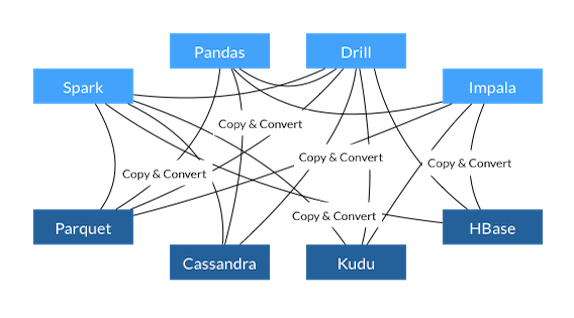
Here is the structure of how we process data before and post arrows:
Instead of copying and converting the data, Arrow understands how to read and operate on the data directly. This data format can be read directly from disk without the need to load it into memory and convert the data. Of course, parts of the data is still going to be loaded into RAM but your data does not have to fit into memory. Arrow uses memory-mapping of its files to load only as much data into memory as necessary and possible.
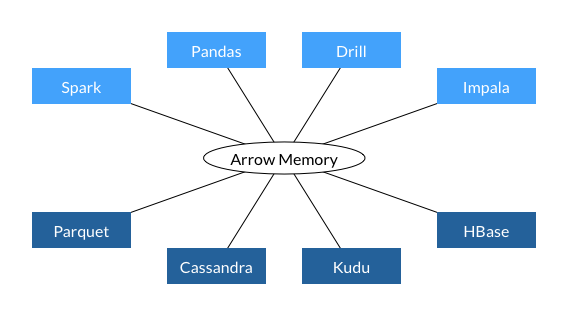
More importantly, the heart of Apache Arrow is its columnar data format.

With the tremendous efficiency and performance improved in data processing, it enables the various ecosystems building upon it, like machine learning models, artificial intelligence or automation systems.
Arrow is used by open-source projects like Apache Parquet, Apache Spark, pandas, and many commercial or closed-source services.
With the future data science open sources developing, Apache Arrow is becoming a hidden champion of data analytics.
Source:
[1]: https://en.wikipedia.org/wiki/Apache_Arrow
[2]: https://maximilianmichels.com/2020/apache-arrow-the-hidden-champion/
[3]: https://arrow.apache.org/
Apache Arrow is used to accelerate analytic workloads within a particular system when data needs to be exchanged with low overhead. It is flexible enough to support most complex data science models.
What is Apache Arrow?
Apache Arrow is a language-agnostic software framework for developing data analytics applications that process columnar data.
It contains a standardized column-oriented memory format that is able to represent flat and hierarchical data for efficient analytic operations on modern CPU and GPU hardware. This reduces or eliminates factors that limit the feasibility of working with large sets of data, such as the cost, volatility, or physical constraints of dynamic random-access memory (dynamic RAM or DRAM).
What problems Apache Arrow are solving?
- In-memory computing
- A standardized columnar storage format
- An IPC and RPC framework for data exchange between processes and nodes respectively
Here is the structure of how we process data before and post arrows:
Instead of copying and converting the data, Arrow understands how to read and operate on the data directly. This data format can be read directly from disk without the need to load it into memory and convert the data. Of course, parts of the data is still going to be loaded into RAM but your data does not have to fit into memory. Arrow uses memory-mapping of its files to load only as much data into memory as necessary and possible.

More importantly, the heart of Apache Arrow is its columnar data format.
If we store the data like this, we have all the column data in one place and can iterate over it efficiently. Not only is this more efficient in terms of extracting values but we can also take advantage of modern CPU architecture. It is very efficient due to caching and pipelining at the processor level, therefore it provides a tremendous performance boost, to a point that it enables new apps which were feasible ever before.
With the tremendous efficiency and performance improved in data processing, it enables the various ecosystems building upon it, like machine learning models, artificial intelligence or automation systems.
Arrow is used by open-source projects like Apache Parquet, Apache Spark, pandas, and many commercial or closed-source services.
With the future data science open sources developing, Apache Arrow is becoming a hidden champion of data analytics.
Source:
[1]: https://en.wikipedia.org/wiki/Apache_Arrow
[2]: https://maximilianmichels.com/2020/apache-arrow-the-hidden-champion/
[3]: https://arrow.apache.org/